The basic idea
Every time a cell divides, it has to give each daughter cell a complete copy of its DNA. A human cell has about 3 billion base pairs of DNA, and the copy needs to be highly accurate. The mechanism that makes this possible is one of biology's most elegant pieces of machinery.
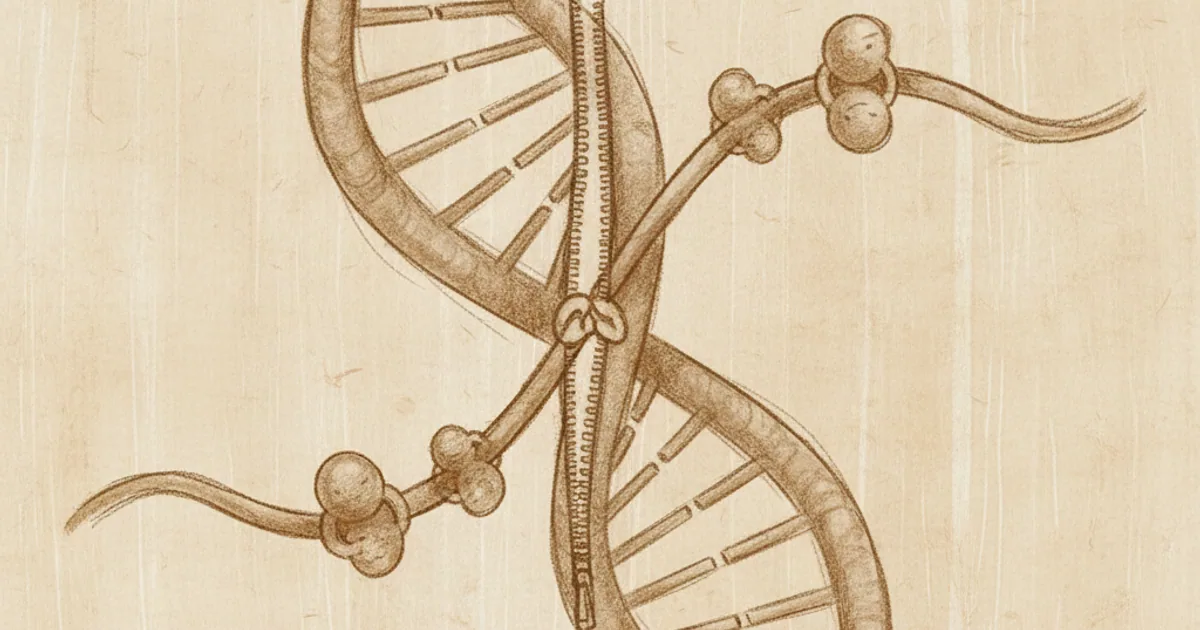
The key insight: DNA is a double helix, two strands wound around each other, and each strand is the complement of the other. If you unzip the helix, each single strand carries enough information to rebuild a complete double helix. You just have to add the matching base at each position.
This means replication, conceptually, has two steps: unzip the helix, then fill in the complement of each separated strand. The reality is more complex than that, but the conceptual picture is clean.
Why "semiconservative"
In 1953, Watson and Crick deduced the double-helix structure of DNA and immediately noticed it suggested a copying mechanism: each strand could template the other. But how exactly?
Three possibilities seemed plausible:
- Conservative: the parent helix stays intact, and a brand-new double helix is built alongside it. After replication: one fully-old DNA, one fully-new.
- Semiconservative: the parent helix unzips, each strand becomes one half of a new helix paired with a freshly-built partner. After replication: two hybrid DNAs, each with one old and one new strand.
- Dispersive: the parent is broken into pieces, each piece gets a new complement, and the pieces are reassembled. After replication: two patchworks.
In 1958, Matthew Meselson and Franklin Stahl ran an experiment using heavy nitrogen labelling to track which strands were old vs new. The result was unambiguous: semiconservative. Each new molecule had one old strand and one new strand.
It's been called "the most beautiful experiment in biology" because the design is so clean and the answer is so clear.
The cast of enzymes
Replication is run by a small army of specialized proteins, each doing one job:
Helicase. The molecular unzipper. It clamps onto the double helix and walks along, prying the two strands apart. Energy comes from ATP. Speed: hundreds to thousands of base pairs per second.
Single-strand binding proteins (SSBs). Coat the separated strands to keep them from snapping back together while they wait to be copied.
DNA polymerase. The actual copy machine. It reads one strand and adds matching bases (A pairs with T, C pairs with G) to build the complementary strand. There are multiple polymerases for different jobs; the main one in humans for bulk replication is polymerase δ (delta) on one strand and polymerase ε (epsilon) on the other.
Primase. DNA polymerase can't start a new strand from scratch; it can only extend an existing one. Primase lays down short RNA primers — a few bases of RNA matched to the template — which polymerase can then extend.
Sliding clamp (PCNA in eukaryotes). A doughnut-shaped protein that grips the polymerase to the DNA so it doesn't fall off after every base.
Ligase. Joins together the fragments that one strand produces (see next section).
Topoisomerase. Manages the twisting tension that builds up ahead of the replication fork. Without it, the DNA would supercoil and seize up.
The lagging-strand twist
Here's the elegant complication. DNA polymerase only works in one direction — it adds bases to the 3' end of a growing strand. But the two parent strands run antiparallel (one goes 5'→3', the other 3'→5'), and replication unzips them in only one direction.
For one strand (the leading strand), this is fine: polymerase can run continuously in the unzipping direction.
For the other (the lagging strand), polymerase has to go backwards. It does this in short bursts called Okazaki fragments, each about 200 bases in eukaryotes. Each fragment is started by a primase laying down a primer, extended by polymerase, then later joined to the previous fragment by ligase.
It's an awkward solution, but it works. The bursty lagging-strand process is one of the reasons replication is the most chemically complex routine event in your cells.
Speed and fidelity
A human cell replicates its entire genome — 3 billion base pairs — in about 8 hours. To pull this off, it doesn't replicate from one starting point; it uses thousands of origins of replication in parallel, each firing at a different time during the synthesis (S) phase of the cell cycle.
Each polymerase makes about one wrong base per 10⁴ to 10⁵. That's already remarkably accurate, but the cell does better:
- Proofreading. DNA polymerase has a built-in exonuclease that snips off the most recent base if it doesn't pair correctly. Errors drop to about 1 per 10⁷.
- Mismatch repair. After replication, a post-replication system scans for any remaining mistakes by comparing the new strand to the old. Errors drop to about 1 per 10⁹ to 10¹⁰.
A billion to ten billion bases per error. Across a 3-billion-base genome, that's somewhere between 0.3 and 3 errors per replication. Most are in non-coding regions where they don't matter; the rest are usually fixed before they cause problems.
If you'd like a guided 5-minute walkthrough of DNA replication with check-yourself quizzes, NerdSip can generate a personalized course on this exact topic.
What goes wrong
The replication machinery is so precise that when it fails, the failures are characteristic:
- Cancer. Many cancers carry mutations in mismatch repair genes (Lynch syndrome, for instance), letting errors accumulate at hundreds of times the normal rate.
- Hereditary diseases. Some inherited disorders (like Werner syndrome) involve broken helicases, causing premature aging-like phenotypes from accumulated DNA damage.
- Antibiotic and chemo drugs. Many work by targeting bacterial or rapidly-dividing replication machinery (sulfa drugs, fluoroquinolones, cisplatin). Cancer cells, which replicate frequently, are more susceptible than normal cells.
The takeaway
DNA replication is the molecular event that lets life propagate. A coordinated team of enzymes unzips the double helix, builds complementary new strands using each old strand as a template, and proofreads the result to a few errors per billion bases. The leading strand goes smoothly; the lagging strand goes in awkward backward fragments. It happens in every dividing cell of every organism, billions of times per day in your body, and the fact that it works as well as it does is one of biology's biggest astonishments.
helicase unzipping the strand like a literal zipper is the image that stuck with me. clear writeup
the proofreading step kind of blew my mind, i had no idea cells double check thier own copying. explains alot about why mutations are actually pretty rare